WEB-MISC weblogic/tomcat .jsp view source attempt-두번째
지난 글에 이어서 룰 개선을 시도해보자. 그러기 위해서는 먼저 탐지된 로그의 패턴 발생 분포를 정확히 파악할 필요가 있다. 로그가 수백 개라면 탐지패턴 확인 작업을 수백 번 반복해야 하는데, 로그가 많을수록 그 작업은 어려울 수 밖에 없다. 패턴매칭 기반 보안솔루션의 정확도 개선이 더딘 이유가 되겠다.그런데 로그라는 텍스트 데이터를 좀더 쉽게 분석할 수 있는 방법이 있다. 불규칙적으로 배열된 텍스트를 동일한 규칙으로 재배열, 즉 텍스트를 정규화하는 것이다.
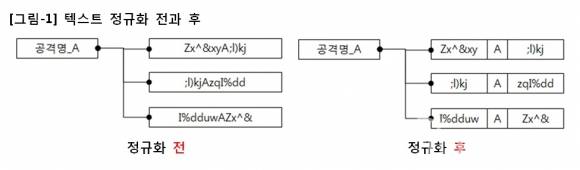
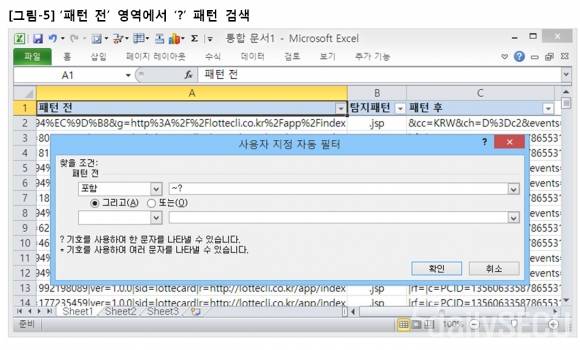
탐지패턴을 기준으로 텍스트를 정규화하면 불규칙한 배열의 텍스트가 규칙적으로 배열되면서 전체 패턴의 맥락 파악이 쉬워진다. 그러기 위해서는 전체 텍스트에서 탐지패턴만을 구분해야 하는데, 이 때 VI의 ‘%s/치환 전 패턴/치환 후 패턴/’ 명령어를 사용한다.
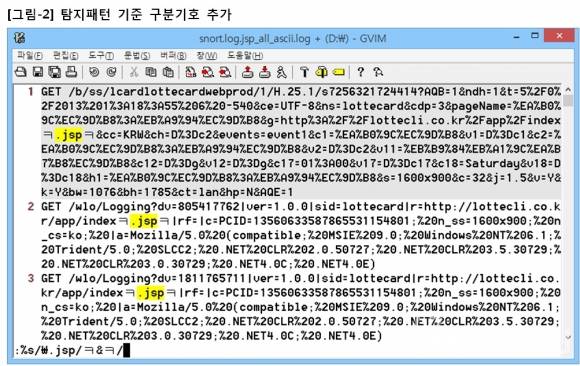
해당 탐지로그는 ‘.jsp’ 라는 필수 탐지패턴을 가지고 있기 때문에 해당 탐지패턴을 기준으로 텍스트 정규화를 시도했으며, 구분기호는 ‘ㅋ’ 을 사용했는데, 다른 패턴과 중복되지 않는다면 어떤 구분기호를 사용해도 상관없다. 참고로 '&' 는 ‘치환 전 패턴’을 의미하는 VI 특수문자이다.
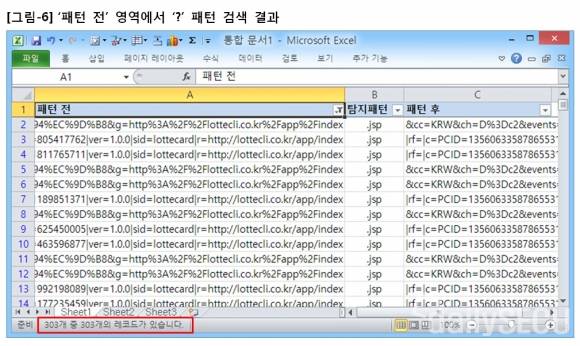
엑셀의 ‘데이터 > 텍스트 나누기’ 기능을 이용해서 텍스트 정규화를 진행한 결과는 [그림-3]과 같다.
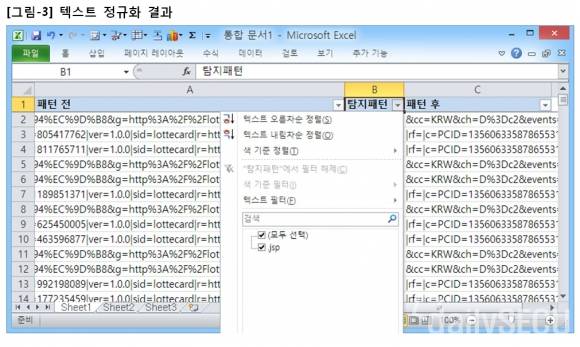
URI 영역에서 인코딩된 ‘.jsp’ 패턴은 보이지 않는다. 한마디로 공격 시도는 없다. 그리고 공격이 아니라면, 즉 인코딩되지 않은 순수 문자열 ‘.jsp’ 패턴은 탐지하지 않아야 한다. 그런데 왜 탐지를 하고 있을까?
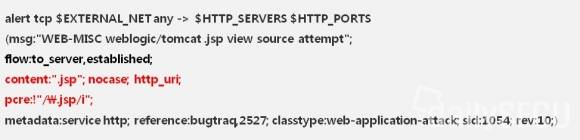
해당 룰과 관련해서 중요한 기술적 배경이 하나 있다. Snort는 룰 검사 전에 'http_inspect' 라는 전처기(preprocessor)를 통해 URL 인코딩된 HTTP 데이터를 미리 디코딩해준다. 다음 2개의 룰은 URL 인코딩되지 않은 '.jsp'는 물론, '.js%70', '%252ejsp' 등 인코딩된 패턴 모두를 탐지한다.

그러나 다음 2개의 룰은 오로지 인코딩되지 않은 순수한 문자열 '.jsp' 패턴만을 탐지한다. 'http_inspect' 전처리기는 'http_uri', 'uricontent' 옵션만을 지원하기 때문이다.

이런 특성을 이용하면 'content'와 'http_uri' 옵션을 이용하여 인코딩되거나, 되지 않은 모든 형태의 '.jsp' 패턴을 검사한 후, 'pcre' 옵션으로 한번 더 검사하여 인코딩되지 않은 패턴만을 걸러낼 수 있다. 아마도 룰 개발자는 [그림-4]와 같은 룰 구조를 원했을 것이다.
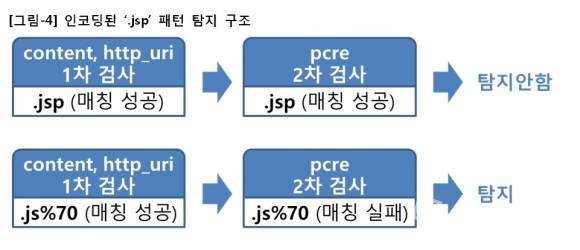
그런데 왜 이런 문제가 발생하고 있을까? 지난 글에서 이미 확인했듯이 탐지로그는 전부 필수 탐지패턴 ‘.jsp’ 전에 ‘?’ 패턴을 포함하고 있다. 즉 JSP 파일이 변수값으로 사용된 패터만을 탐지하고 있다.
아마도 룰 개발자는 줄바꿈문자(n)와 공백(s)을 제외해서 검사 범위를 URI 영역으로 제한하고, ‘?’ 패턴을 제외해서 변수값으로 사용된 JSP 파일 패턴을 제외하려고 했던 것으로 보인다. 그러나 그렇게 하기 위해서는 회피 옵션(!)을 사용하지 않았어야 했다. 룰 개발자가 PCRE 옵션에 사용할 정규표현식을 작성하는 과정에서 고민을 너무 많이 한 나머지, 정규표현식 잘 만들어놓고 정작 엉뚱한 부분에서 실수를 한 게 아닐까 싶다.
그런데 해당 취약점의 특징을 잘 살펴보면 사실 그렇게 복잡한 정규표현식이 필요하지는 않다. 해당 취약점을 이용한 공격을 탐지하기 위해서는 URI 영역의 ‘.jsp’ 패턴, 즉 파일 확장자 영역의 인코딩 여부만 검사하면 된다.
다음과 같이 룰을 수정하면 [그림-4]의 구조를 이용해서 인코딩된 ‘.jsp’ 패턴만을 탐지할 수 있다. content와 pcre 옵션이 동일한 패턴을 검사하므로, content 검사가 성공한다면 pcre는 같은 패턴을 한번 더 검사한다. 즉 content가 URI 영역을 검사했다면 pcre 역시 URI 영역을 검사하게 된다. pcre 검사 범위를 URI로 제한하기 위해 복잡한 정규표현식을 사용할 필요는 없었던 것이다.
그런데 해당 취약점의 특징을 잘 살펴보면 사실 그렇게 복잡한 정규표현식이 필요하지는 않다. 해당 취약점을 이용한 공격을 탐지하기 위해서는 URI 영역의 ‘.jsp’ 패턴, 즉 파일 확장자 영역의 인코딩 여부만 검사하면 된다.
다음과 같이 룰을 수정하면 [그림-4]의 구조를 이용해서 인코딩된 ‘.jsp’ 패턴만을 탐지할 수 있다. content와 pcre 옵션이 동일한 패턴을 검사하므로, content 검사가 성공한다면 pcre는 같은 패턴을 한번 더 검사한다. 즉 content가 URI 영역을 검사했다면 pcre 역시 URI 영역을 검사하게 된다. pcre 검사 범위를 URI로 제한하기 위해 복잡한 정규표현식을 사용할 필요는 없었던 것이다.
수집된 데이터의 분석 결과 룰 수정의 근거를 마련할 수 있었으며, 그 과정에서 정규표현식의 중요성에 대해서도 알 수 있었다. 그리고 보안관제 업무가 룰 개선으로 이어지지 않고, 로그의 정오탐 여부 판정에서 그친다면 어떤 문제가 발생하는지 역시 알 수 있었다.
수집된 데이터의 양이 많아질수록 분석 결과가 정확해질 가능성은 높아지며, 결국 룰 정확도 역시 높아질 것이다. 물론 로그 샘플링을 통해서도 비슷한 결과를 가져올 수 있지만 데이터 전수조사는 샘플링의 오차 한계를 극복하고, 측정된 정량적 근거자료는 샘플링과는 비교할 수 없는 설득력을 제공해준다. 빅데이터가 각광받는 이유가 아닐까 한다.
특정 룰에 의해 발생한 전체 로그의 분석을 통해 룰의 문제점 및 개발 의도와 일치 여부를 확인하고 개선 근거를 확보하는 사례를 살펴봤다. 컴퓨터 환경에서 'Garbage in Garbage out' 법칙은 정말 진리인 것 같다. 룰이 엉터리면 엉터리 로그인 오탐이 나올 수 밖에 없는 것이다. 반면 Garbage output을 잘 분석하면 input의 품질은 얼마든지 높일 수 있다.
처음부터 완벽한 룰을 만들기는 어렵지만, 그 룰의 입력 결과인 로그를 잘 정리하면 더 좋은 룰을 만들 수 있다. 사고 단위가 아닌 데이터 단위 분석이 필요한 이유가 될 것이다.
[글. <빅데이터 분석으로 살펴본 IDS와 보안관제의 완성> 저자 강명훈 / kangmyounghun.blogspot.kr]
★정보보안 대표 미디어 데일리시큐!★
■ 보안 사건사고 제보 하기
★정보보안 대표 미디어 데일리시큐 / Dailysecu, Korea's leading security media!★
저작권자 © 데일리시큐 무단전재 및 재배포 금지
